快递单ocr检测
- 1.总结
- 2.需求
- 3.方案
- 4.面单定位
- 4.1反转图片扩充数据集
- 4.2新的标注方式
- 4.3json2yolo
- 4.4yolov5推理
- 5.paddleocr
- 5.1 数据标注
- 5.2 文本检测训练
- 5.3 文本识别训练
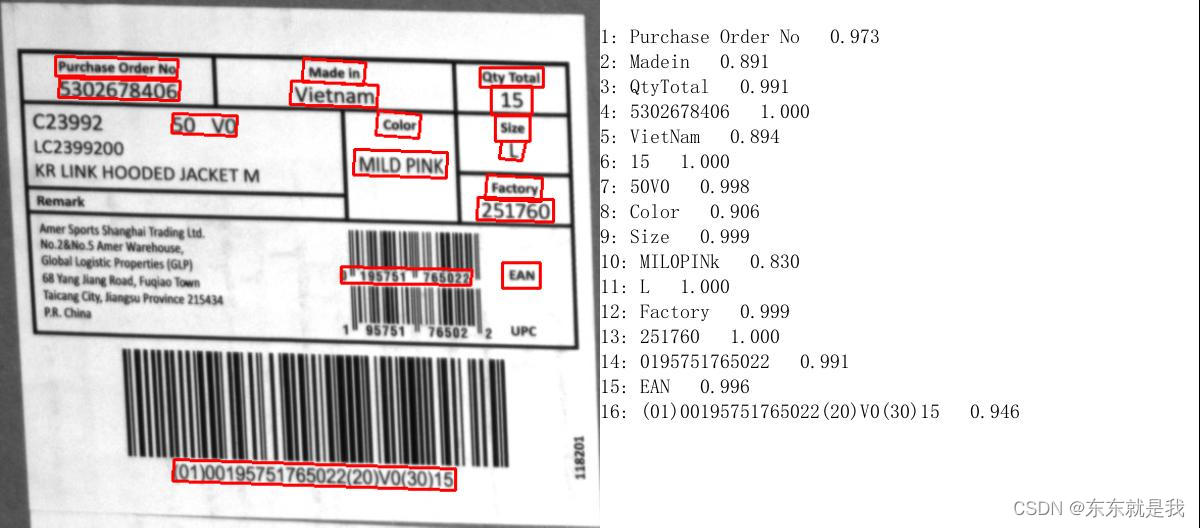
- 检测结果
1.总结
按照惯例,先吐槽一下。反正也没人看我比比歪歪。做事全部藏着掖着,真有你们的。如果需求都不对技术开放,那还要技术干嘛,自己玩不是更好??一天天的耍猴一样的耍我玩,真是够够的
2.需求
快递单的关键字ocr识别,那简单啊,直接使用paddleocr的代码不就好了。但是客户的需求显然没那么简单,不然也轮不到我。。。,总结下来难点有4个。
1.大视野
2.关键字提取
3.多种模版
4.多面单

3.方案
这么大的事业完全送去做ocr不现实,一个是速度太慢,二是精度不高。所以只能先分割面单,然后在ocr,最后再关键字匹配。
1.yolov5 面单定位
2.paddleocr 字符识别
大的技术架构就是这样,具体的细节下面再说
4.面单定位
老生常谈的yolov5,就不在过多的介绍。数据集需要的可以自取面单数据
因为我的使用的相机是2000w的所以,图片分辨率是5440*2800。所以选择的模型是yolov5n6
image_size =1280
4.1反转图片扩充数据集
import json
import os.path
import numpy as np
from labelme import utils
import cv2
file_path=r'G:\sick\420_1'
file_path2=r'G:\sick\420_2'
for file_name in os.listdir(file_path):
if file_name.endswith('.json'):
file_num=file_name.split('.')[0]+'_1'
json_path=os.path.join(file_path,file_name)
json_data = json.load(open(json_path))
main_coord = np.array([5440, 2800])
# 如果'points'是NumPy数组,先转换为列表
json_data['shapes'][0]['points'] = (main_coord - json_data['shapes'][0]['points']).tolist()
json_data['shapes'][0]['label'] = 'flip_order'
img = utils.img_b64_to_arr(json_data['imageData'])
mask_img = cv2.rotate(img, cv2.ROTATE_180)
save_image_name = file_num+'.jpg'
save_json_name = file_num+'.json'
cv2.imwrite(os.path.join(file_path2,save_image_name),mask_img)
json_data['imageData']=utils.img_arr_to_b64(mask_img)
with open(os.path.join(file_path2,save_json_name), 'w') as json_file:
json.dump(json_data, json_file)
4.2新的标注方式
segment anything 使用这个分割模型检测图片上所有的物体,然后通过长宽比和面积大小筛选我们需要的面单,生成对应json
# -*- coding: utf-8 -*-
import os
import cv2
import sys
import numpy as np
import base64
import json
import os.path as osp
import PIL.Image
import io
sys.path.append("..")
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator, SamPredictor
def load_image_file(filename):
try:
image_pil = PIL.Image.open(filename)
except IOError:
return
with io.BytesIO() as f:
ext = osp.splitext(filename)[1].lower()
if ext in [".jpg", ".jpeg"]:
format = "JPEG"
else:
format = "PNG"
image_pil.save(f, format=format)
f.seek(0)
return f.read()
def show_anns(anns, file_name):
if len(anns) == 0:
return
sorted_anns = sorted(anns, key=(lambda x: x['area']), reverse=True)
image = load_image_file(os.path.join(file_path, file_name))
image_base64_str = base64.b64encode(image).decode('utf-8')
shapes = []
# 创建保存图片的字典
data = {"version": "4.5.6", "flags": {}, 'shapes': shapes, "imagePath": file_name, "imageHeight": 2800,
"imageWidth": 5440,
"imageData": image_base64_str}
for ann in sorted_anns:
if ann['area'] > 20000 and ann['area'] < 30000:
mask_array = ann['segmentation']
# 寻找轮廓
# 将布尔类型数组转换为灰度图像
mask = np.uint8(mask_array) * 255
contours, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 获取最大轮廓
max_contour = max(contours, key=cv2.contourArea)
# 获取最小外接矩形
rect = cv2.minAreaRect(max_contour)
# 获取矩形的四个顶点
box = cv2.boxPoints(rect)
box = np.intp(box)
box_abs = np.abs(box) # 使用绝对值将坐标转换为正数
# 将顶点坐标按比例缩放回原始图像大小
box_restored = np.round(box_abs * [scale_y,scale_x]).astype(np.int32)
box = {
"label": "order",
"points": box_restored.tolist(),
"group_id": None,
"shape_type": "polygon",
"flags": {}
}
shapes.append(box)
# 将字典保存为 JSON 文件
with open(file_name.split('.')[0]+'.json', 'w') as json_file:
json.dump(data, json_file)
# 加载模型
sam_checkpoint = "sam_vit_h_4b8939.pth"
model_type = "vit_h"
device = "cuda"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
mask_generator = SamAutomaticMaskGenerator(sam)
file_path = 'sick_ocr'
file_names = os.listdir(file_path)
scale_x = 4
scale_y = 4
# 单张图片推理
for file_name in file_names:
if file_name.endswith('jpg'):
image_file = os.path.join(file_path, file_name)
image = cv2.imread(image_file)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image_resize = cv2.resize(image, (1024, 1024))
# 计算缩放比例
masks = mask_generator.generate(image_resize)
show_anns(masks, file_name)
# 筛选area为制定大小
4.3json2yolo
'''
Created on Aug 18, 2021
@author: xiaosonh
'''
import os
import sys
import argparse
import shutil
import math
from collections import OrderedDict
import json
import cv2
import PIL.Image
from sklearn.model_selection import train_test_split
from labelme import utils
class Labelme2YOLO(object):
def __init__(self, json_dir, to_seg=False):
self._json_dir = json_dir
self._label_id_map = self._get_label_id_map(self._json_dir)
self._to_seg = to_seg
i = 'YOLODataset'
i += '_seg/' if to_seg else '/'
self._save_path_pfx = os.path.join(self._json_dir, i)
def _make_train_val_dir(self):
self._label_dir_path = os.path.join(self._save_path_pfx, 'labels/')
self._image_dir_path = os.path.join(self._save_path_pfx, 'images/')
for yolo_path in (os.path.join(self._label_dir_path + 'train/'),
os.path.join(self._label_dir_path + 'val/'),
os.path.join(self._image_dir_path + 'train/'),
os.path.join(self._image_dir_path + 'val/')):
if os.path.exists(yolo_path):
shutil.rmtree(yolo_path)
os.makedirs(yolo_path)
def _get_label_id_map(self, json_dir):
label_set = set()
for file_name in os.listdir(json_dir):
if file_name.endswith('json'):
json_path = os.path.join(json_dir, file_name)
data = json.load(open(json_path))
for shape in data['shapes']:
label_set.add(shape['label'])
return OrderedDict([(label, label_id) \
for label_id, label in enumerate(label_set)])
def _train_test_split(self, folders, json_names, val_size):
if len(folders) > 0 and 'train' in folders and 'val' in folders:
train_folder = os.path.join(self._json_dir, 'train/')
train_json_names = [train_sample_name + '.json' \
for train_sample_name in os.listdir(train_folder) \
if os.path.isdir(os.path.join(train_folder, train_sample_name))]
val_folder = os.path.join(self._json_dir, 'val/')
val_json_names = [val_sample_name + '.json' \
for val_sample_name in os.listdir(val_folder) \
if os.path.isdir(os.path.join(val_folder, val_sample_name))]
return train_json_names, val_json_names
train_idxs, val_idxs = train_test_split(range(len(json_names)),
test_size=val_size)
train_json_names = [json_names[train_idx] for train_idx in train_idxs]
val_json_names = [json_names[val_idx] for val_idx in val_idxs]
return train_json_names, val_json_names
def convert(self, val_size):
json_names = [file_name for file_name in os.listdir(self._json_dir) \
if os.path.isfile(os.path.join(self._json_dir, file_name)) and \
file_name.endswith('.json')]
folders = [file_name for file_name in os.listdir(self._json_dir) \
if os.path.isdir(os.path.join(self._json_dir, file_name))]
train_json_names, val_json_names = self._train_test_split(folders, json_names, val_size)
self._make_train_val_dir()
# convert labelme object to yolo format object, and save them to files
# also get image from labelme json file and save them under images folder
for target_dir, json_names in zip(('train/', 'val/'),
(train_json_names, val_json_names)):
for json_name in json_names:
json_path = os.path.join(self._json_dir, json_name)
json_data = json.load(open(json_path))
print('Converting %s for %s ...' % (json_name, target_dir.replace('/', '')))
img_path = self._save_yolo_image(json_data,
json_name,
self._image_dir_path,
target_dir)
yolo_obj_list = self._get_yolo_object_list(json_data, img_path)
self._save_yolo_label(json_name,
self._label_dir_path,
target_dir,
yolo_obj_list)
print('Generating dataset.yaml file ...')
self._save_dataset_yaml()
def convert_one(self, json_name):
json_path = os.path.join(self._json_dir, json_name)
json_data = json.load(open(json_path))
print('Converting %s ...' % json_name)
img_path = self._save_yolo_image(json_data, json_name,
self._json_dir, '')
yolo_obj_list = self._get_yolo_object_list(json_data, img_path)
self._save_yolo_label(json_name, self._json_dir,
'', yolo_obj_list)
def _get_yolo_object_list(self, json_data, img_path):
yolo_obj_list = []
img_h, img_w, _ = cv2.imread(img_path).shape
for shape in json_data['shapes']:
# labelme circle shape is different from others
# it only has 2 points, 1st is circle center, 2nd is drag end point
if shape['shape_type'] == 'circle':
yolo_obj = self._get_circle_shape_yolo_object(shape, img_h, img_w)
else:
yolo_obj = self._get_other_shape_yolo_object(shape, img_h, img_w)
yolo_obj_list.append(yolo_obj)
return yolo_obj_list
def _get_circle_shape_yolo_object(self, shape, img_h, img_w):
label_id = self._label_id_map[shape['label']]
obj_center_x, obj_center_y = shape['points'][0]
radius = math.sqrt((obj_center_x - shape['points'][1][0]) ** 2 +
(obj_center_y - shape['points'][1][1]) ** 2)
if self._to_seg:
retval = [label_id]
n_part = radius / 10
n_part = int(n_part) if n_part > 4 else 4
n_part2 = n_part << 1
pt_quad = [None for i in range(0, 4)]
pt_quad[0] = [[obj_center_x + math.cos(i * math.pi / n_part2) * radius,
obj_center_y - math.sin(i * math.pi / n_part2) * radius]
for i in range(1, n_part)]
pt_quad[1] = [[obj_center_x * 2 - x1, y1] for x1, y1 in pt_quad[0]]
pt_quad[1].reverse()
pt_quad[3] = [[x1, obj_center_y * 2 - y1] for x1, y1 in pt_quad[0]]
pt_quad[3].reverse()
pt_quad[2] = [[obj_center_x * 2 - x1, y1] for x1, y1 in pt_quad[3]]
pt_quad[2].reverse()
pt_quad[0].append([obj_center_x, obj_center_y - radius])
pt_quad[1].append([obj_center_x - radius, obj_center_y])
pt_quad[2].append([obj_center_x, obj_center_y + radius])
pt_quad[3].append([obj_center_x + radius, obj_center_y])
for i in pt_quad:
for j in i:
j[0] = round(float(j[0]) / img_w, 6)
j[1] = round(float(j[1]) / img_h, 6)
retval.extend(j)
return retval
obj_w = 2 * radius
obj_h = 2 * radius
yolo_center_x = round(float(obj_center_x / img_w), 6)
yolo_center_y = round(float(obj_center_y / img_h), 6)
yolo_w = round(float(obj_w / img_w), 6)
yolo_h = round(float(obj_h / img_h), 6)
return label_id, yolo_center_x, yolo_center_y, yolo_w, yolo_h
def _get_other_shape_yolo_object(self, shape, img_h, img_w):
label_id = self._label_id_map[shape['label']]
if self._to_seg:
retval = [label_id]
for i in shape['points']:
i[0] = round(float(i[0]) / img_w, 6)
i[1] = round(float(i[1]) / img_h, 6)
retval.extend(i)
return retval
def __get_object_desc(obj_port_list):
__get_dist = lambda int_list: max(int_list) - min(int_list)
x_lists = [port[0] for port in obj_port_list]
y_lists = [port[1] for port in obj_port_list]
return min(x_lists), __get_dist(x_lists), min(y_lists), __get_dist(y_lists)
obj_x_min, obj_w, obj_y_min, obj_h = __get_object_desc(shape['points'])
yolo_center_x = round(float((obj_x_min + obj_w / 2.0) / img_w), 6)
yolo_center_y = round(float((obj_y_min + obj_h / 2.0) / img_h), 6)
yolo_w = round(float(obj_w / img_w), 6)
yolo_h = round(float(obj_h / img_h), 6)
return label_id, yolo_center_x, yolo_center_y, yolo_w, yolo_h
def _save_yolo_label(self, json_name, label_dir_path, target_dir, yolo_obj_list):
txt_path = os.path.join(label_dir_path,
target_dir,
json_name.replace('.json', '.txt'))
with open(txt_path, 'w+') as f:
for yolo_obj_idx, yolo_obj in enumerate(yolo_obj_list):
yolo_obj_line = ""
for i in yolo_obj:
yolo_obj_line += f'{i} '
yolo_obj_line = yolo_obj_line[:-1]
if yolo_obj_idx != len(yolo_obj_list) - 1:
yolo_obj_line += '\n'
f.write(yolo_obj_line)
def _save_yolo_image(self, json_data, json_name, image_dir_path, target_dir):
img_name = json_name.replace('.json', '.png')
img_path = os.path.join(image_dir_path, target_dir, img_name)
if not os.path.exists(img_path):
img = utils.img_b64_to_arr(json_data['imageData'])
PIL.Image.fromarray(img).save(img_path)
return img_path
def _save_dataset_yaml(self):
yaml_path = os.path.join(self._save_path_pfx, 'dataset.yaml')
with open(yaml_path, 'w+') as yaml_file:
yaml_file.write('train: %s\n' % \
os.path.join(self._image_dir_path, 'train/'))
yaml_file.write('val: %s\n\n' % \
os.path.join(self._image_dir_path, 'val/'))
yaml_file.write('nc: %i\n\n' % len(self._label_id_map))
names_str = ''
for label, _ in self._label_id_map.items():
names_str += "'%s', " % label
names_str = names_str.rstrip(', ')
yaml_file.write('names: [%s]' % names_str)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--json_dir', type=str,
help='Please input the path of the labelme json files.')
parser.add_argument('--val_size', type=float, nargs='?', default=0.1,
help='Please input the validation dataset size, for example 0.1 ')
parser.add_argument('--json_name', type=str, nargs='?', default=None,
help='If you put json name, it would convert only one json file to YOLO.')
parser.add_argument('--seg', action='store_true',
help='Convert to YOLOv5 v7.0 segmentation dataset')
args = parser.parse_args(sys.argv[1:])
convertor = Labelme2YOLO(args.json_dir, to_seg=args.seg)
if args.json_name is None:
convertor.convert(val_size=args.val_size)
else:
convertor.convert_one(args.json_name)
4.4yolov5推理
模型链接
import time
from typing import List, Optional
import cv2
import numpy as np
import onnxruntime as ort
import random
def letterbox(img: Optional[np.arange], new_shape: List = (1280, 1280), color: object = (114, 114, 114), ) -> np.arange:
"""Resize and pad image while meeting stride-multiple constraints
Args:
img (_type_): _description_
new_shape (tuple, optional): _description_. Defaults to (256, 256).
color (tuple, optional): _description_. Defaults to (114, 114, 114).
Returns:
_type_: _description_
"""
shape = img.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
# Compute padding
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return img, r, (dw, dh)
class Model:
def __init__(self, model_path: str, cuda: bool) -> None:
"""Load model
Args:
model_path (str): _description_
cuda (str): _description_
"""
providers = ['CUDAExecutionProvider', 'CPUExecutionProvider'] if cuda else ['CPUExecutionProvider']
self.session = ort.InferenceSession(model_path, providers=providers)
def detect(self, img: Optional[np.array], shape: List[int] = None, ) -> Optional[np.array]:
"""检测
Args:
img (Optional[np.array]): 图片
shape (List[int], optional): 图片大小. Defaults to None.
Returns:
Optional[np.array]: 一个大的box和2个小的box为一组
"""
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
image = img.copy()
if shape is None:
shape = [1280, 1280]
# 图片缩放
image, ratio, dwdh = letterbox(image, shape)
# Convert
# img=np.repeat(img[:, :, np.newaxis], 3, axis=2)
image = image.transpose((2, 0, 1)) # 3x416x416
image = np.expand_dims(image, 0)
image = np.ascontiguousarray(image)
im = image.astype(np.float32)
im /= 255
outname = ['output']
inp = {'images': im}
outputs = self.session.run(outname, inp)[0]
outputs = outputs[:, 1:] # 去掉batch
# 少于3个
# box还原原图大小
boxes = outputs[:, 0:4] # xyxy
boxes -= np.array(dwdh * 2)
boxes /= ratio
return outputs
5.paddleocr
5.1 数据标注
使用paddleocr提供的标注工具paddlelabel,这个是我自己标注的,我只标注了和业务相关的检测区域,这样训练可以减少时间。
面单
5.2 文本检测训练
模型:ch_PP-OCR_V3_det_student
权重:en_PP-OCRv3_det_distill_train/student.pdparams
5.3 文本识别训练
模型:en_PP-OCRv4_rec.yml
权重:en_PP-OCRv4_rec_train/best_accuracy.pdparams
检测结果